

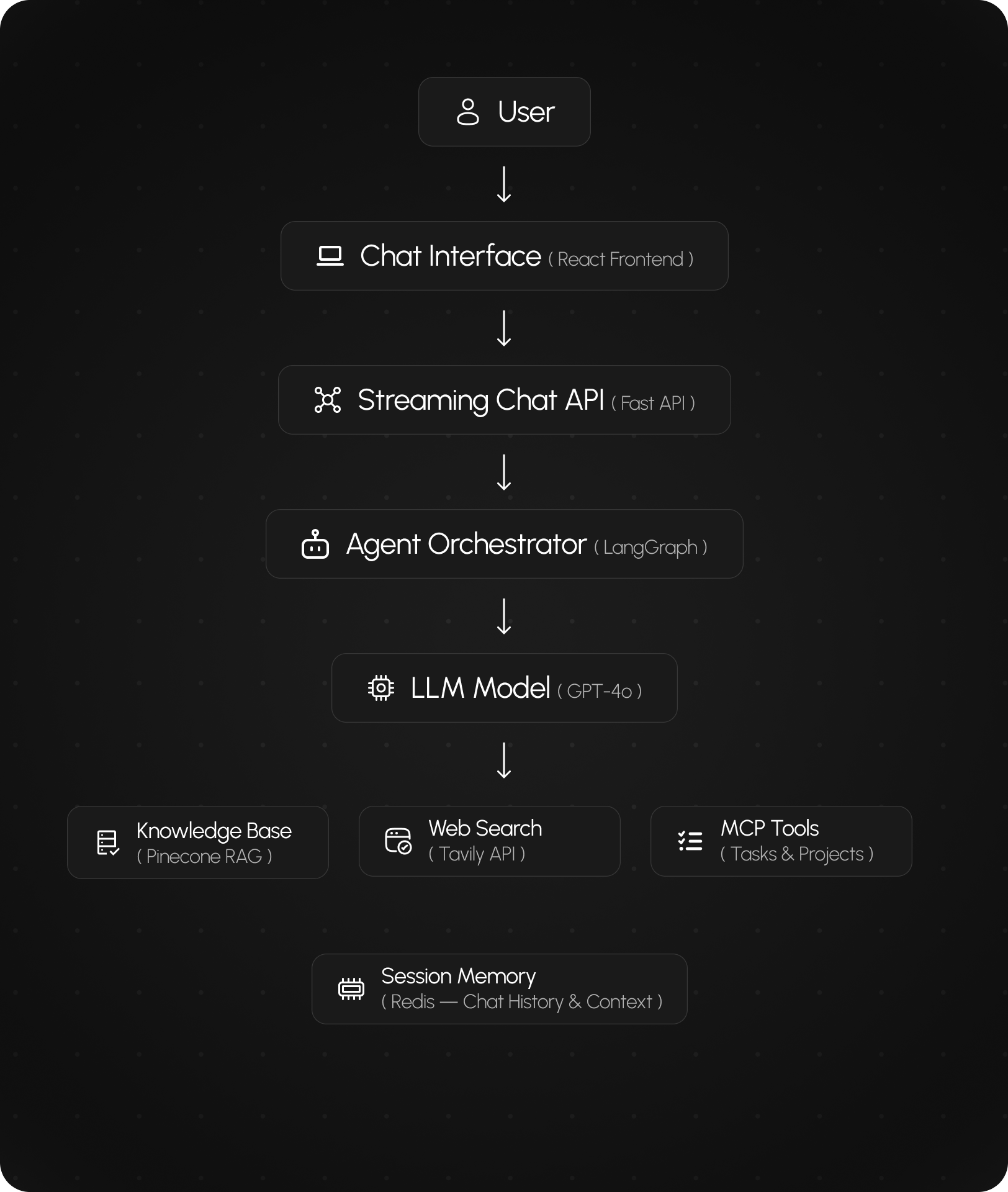
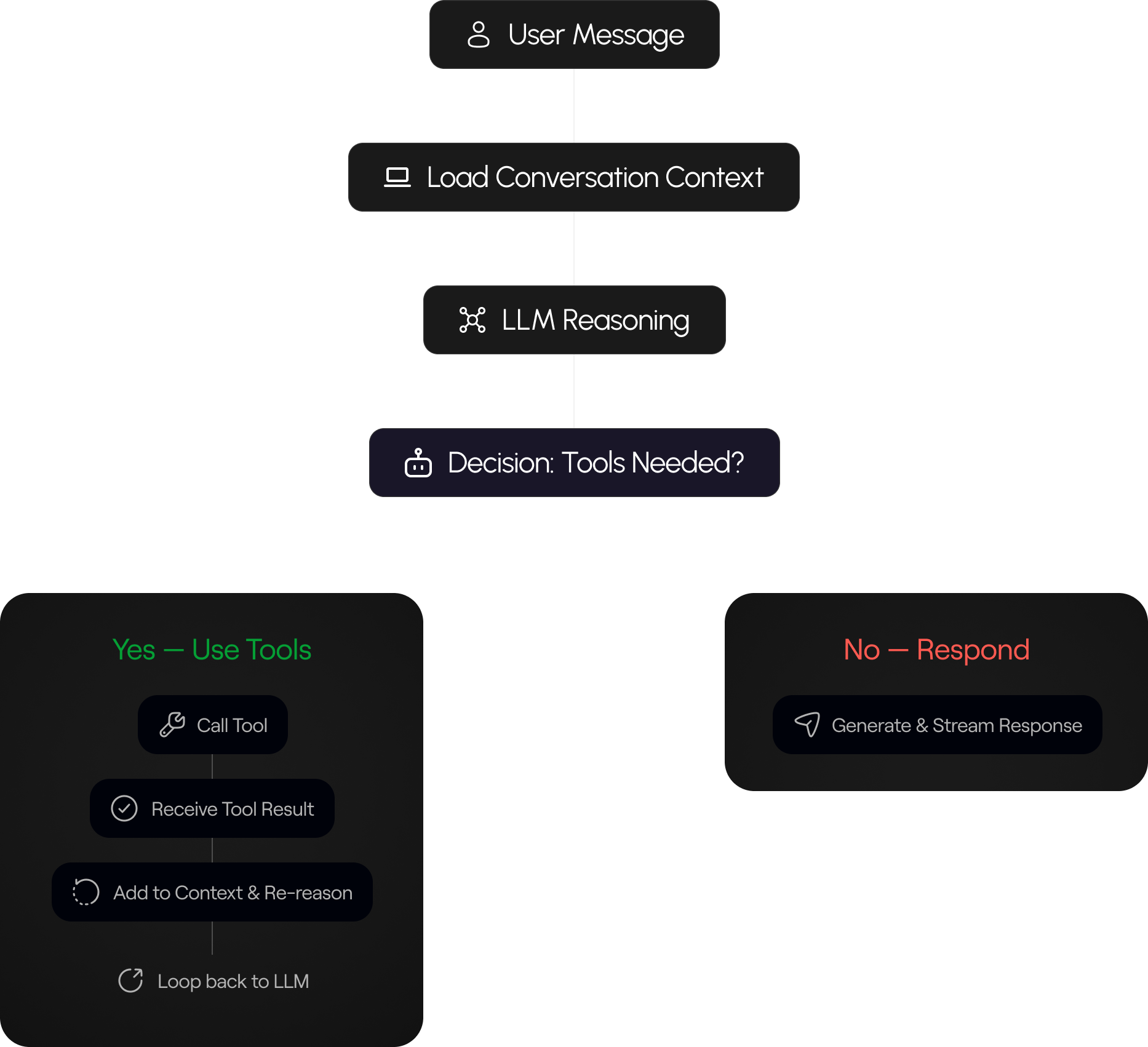
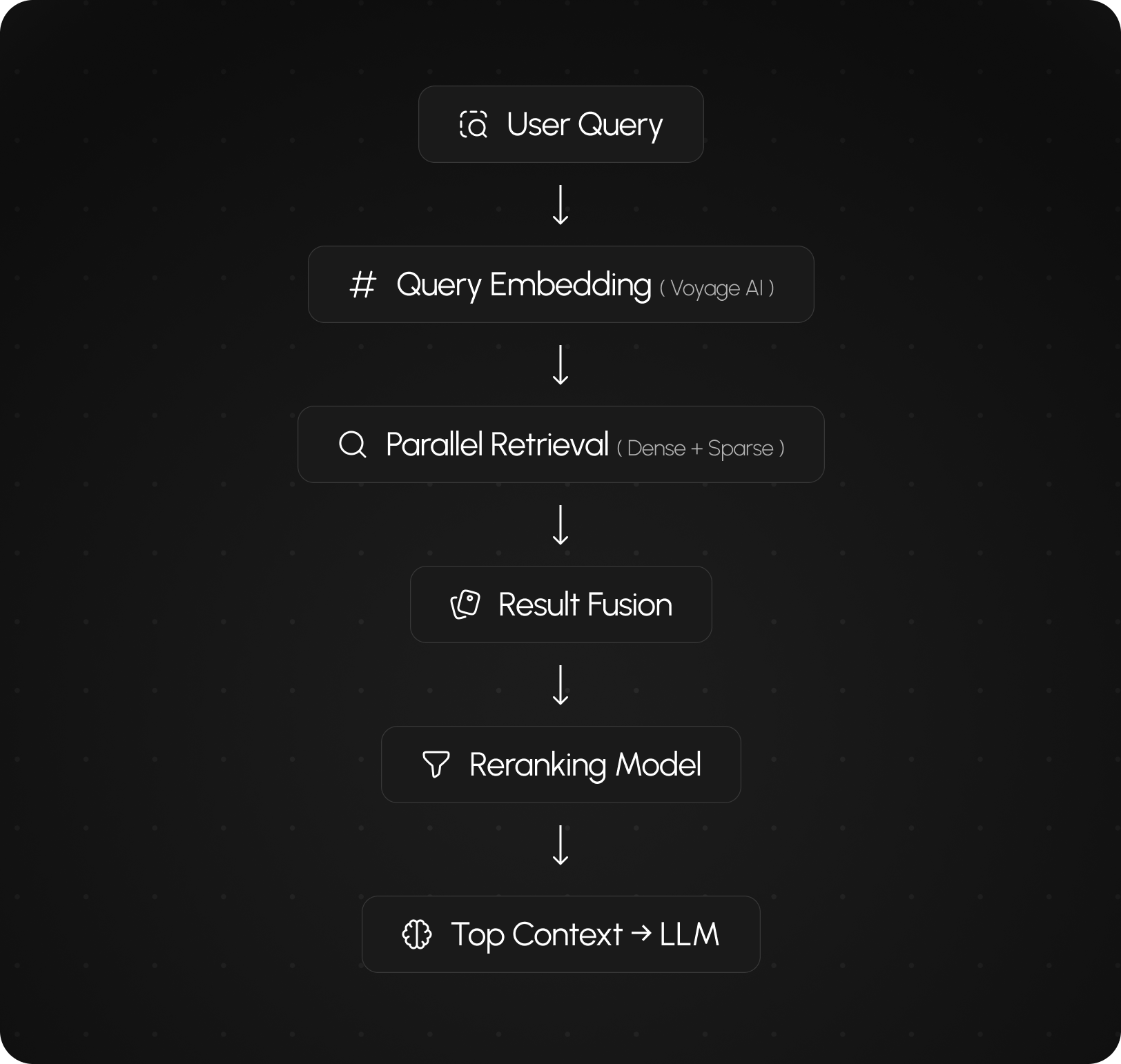
Features | Streaming AI Chat, Tool Calling, RAG Retrieval
Role | AI Engineer / Backend Engineer
Stack | FastAPI, LangGraph, LangChain, Pinecone, Redis













Features | Streaming AI Chat, Tool Calling, RAG Retrieval
Role | AI Engineer / Backend Engineer
Stack | FastAPI, LangGraph, LangChain, Pinecone, Redis